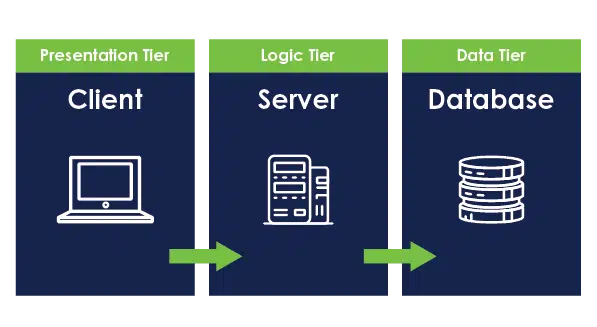
Discover Microsoft Fabric
The future of data management has arrived - Microsoft Fabric is revolutionizing how you access, oversee, and leverage data and insights. Unify all data sources and analytics systems into one unified, AI-driven platform. What is…